世界上有各种各样的残障人士,这些人或不能说话,或听不见声音。聋人,是听力因先天遗传或后天人为因素而受损的残疾人,也叫听力障碍者,简称听障人。根据最近的全国人口普查统计,全中国大约有2700多万听障人,包括弱听、重听、老化聋等。因为各种不方便让其在这个世界上生活极为不方便。比如有人敲门,水龙头忘关、孩子在卧室里啼哭,可是“听障人”他们听不见。利用人工智能,让模型学习各种声音,使用开源硬件-行空板采集声音,通过物联网将相应文字信息发送给Arduino主板在显示屏上显示并利用灯光提醒,并且利用micro:bit制作的手表进行文字、灯光加震动提醒,让“听障人”看见、感触到声音。

【音频信号】
声音以音频信号的形式表示,音频信号具有频率、带宽、分贝等参数,音频信号一般可表示为振幅和时间的函数。这些声音有多种格式,因此计算机可以对其进行读取和分析。例如:mp3 格式、WMA (Windows Media Audio) 格式、wav (Waveform Audio File) 格式。
【语谱图】
语谱图是二战时期发明的一种语音频谱图,一般是通过处理接收的时域信号得到频谱图。
语谱图是频谱分析视图,如果针对语音数据的话,叫语谱图。语谱图的横坐标是时间,纵坐标是频率,坐标点值为语音数据能量。由于是采用二维平面表达三维信息,所以能量值的大小是通过颜色来表示的,颜色深,表示该点的语音能量越强。
语音的时域分析和频域分析是语音分析的两种重要方法,但是都存在着局限性。时域分析对语音信号的频率特性没有直观的了解,频域特性中又没有语音信号随时间的变化关系。而语谱图综合了时域和频域的优点,明显的显示出了语音频谱随时间的变化情况、语谱图的横轴为时间,纵轴为频率,任意给定频率成分在给定时刻的强弱用颜色深浅来表示。颜色深的,频谱值大,颜色浅的,频谱值小。语谱图上不同的黑白程度形成不同的纹路,称之为声纹,不同讲话者的声纹是不一样的,可用作声纹识别。
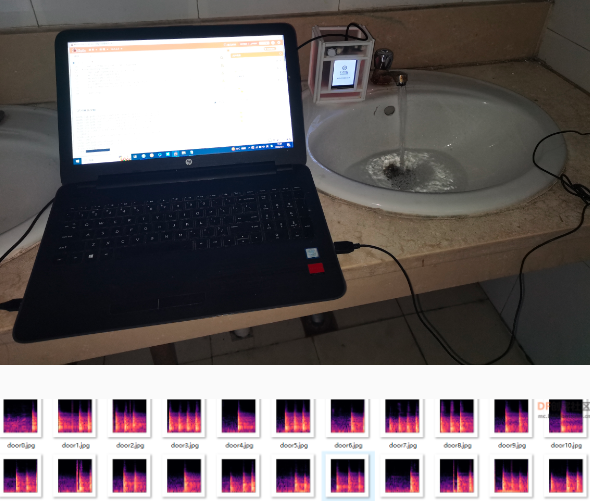
使用Librosa库批量生成各类声音的语谱图,如敲门声、水龙头流水声、婴儿啼哭声、警报声等。Librosa是一个用于音频、音乐分析、处理的python工具包,一些常见的时频处理、特征提取、绘制声音图形等功能应有尽有,功能十分强大。
【录制音频】
使用pyaudio库这个可以进行录音,生成wav文件。PyAudio 提供了 PortAudio 的 Python 语言版本,这是一个跨平台的音频 I/O 库,使用 PyAudio 你可以在 Python 程序中播放和录制音频。为PoTaTudio提供Python绑定,跨平台音频I/O库。使用PyAudio,您可以轻松地使用Python在各种平台上播放和录制音频。
【硬件制作过程】
一、行空板主控
按钮接行空板引脚21(用于关闭提醒),LED灯接引脚22(用于亮灯提醒)。
二、“掌控板”手表
将震动马达接“掌控宝”的M2接口,并粘在表带上。当掌控板收到信息后,启动震动马达开始震动,提醒“听障人”查看屏幕提示信息。

【训练模型】
将图片上传到“英艻AI训练平台”进行模型训练。类型有[size=18.6667px]“background”[size=18.6667px]、“door”、“water”。
【行空板推理】
下载模型,放到行空板程序相应目录。
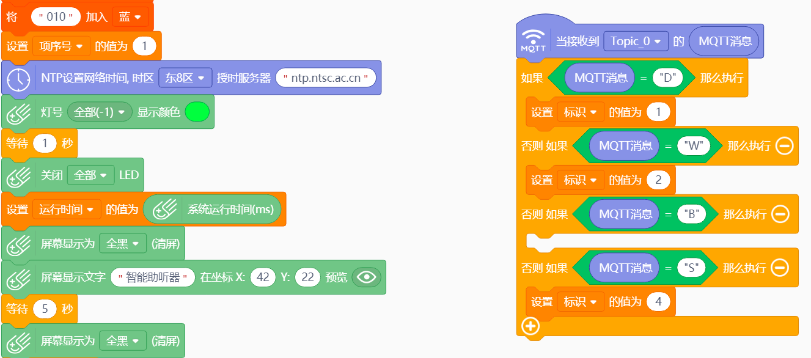
利用行空板板载麦克风采集声音,利用matplotlib变换成图片,使用keras加载训练好的模型“keras_model.h5”,进行预测出声音类型。点亮LED灯并通过物联网发送相关信息指令。

【掌控板手表程序】
通过物联网接收行空板传来的指令,屏幕显示相应信息,板载LED灯循环闪烁,并驱动马达震动。
通过利用人工智能和物联网技术,我们可以为听障人士创造一个更加便利和包容的世界。通过让模型学习各种声音,并使用开源硬件采集声音,我们可以通过文字信息、显示屏、灯光和震动等方式,让听障人士能够看见、感受到声音的存在。这种技术的应用,不仅可以帮助听障人士更好地融入社会和生活,还能提高他们的生活质量和安全感。
关于行空板—“AI助听器”项目的详细实现过程,请访问DF创客社区了解更多。
上海智位机器人
上海智位机器人成立于2010年,是全球领先的从事开源硬件、机器人产品和科创教育的高科技企业,打造了DFRobot、蘑菇云科创教育等品牌,是国内最早的创客理念引入者和倡导者,创客教育的开拓者和引领者。旗下拥有中国最大的线上DF创客社区和国家级创客空间——蘑菇云创客空间,提供丰富的线上和线下学习资源,构建了一个自由、开放和富于创造力的交流空间。其Gravity产品已被全球超过100万开发者选用。合作伙伴包括微软、英特尔、Autodesk、霍尼韦尔、NASA、MIT等知名厂商和机构。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。